在数字化转型的浪潮中,数据中台已成为企业挖掘数据价值的核心引擎。然而,传统开发模式下的高门槛、长周期、高风险问题,让许多企业陷入“建中台难,用中台更难”的困境。本文将从技术视角拆解数据中台的痛点与解法,探讨一种无需代码的新路径。
技术门槛:业务与开发的“语言鸿沟” 某零售企业曾因库存预测模型开发陷入僵局:业务部门提出需求后,IT团队需耗费3周时间理解业务逻辑、构建技术方案,最终交付的模型却因参数偏差导致预测准确率不足60%。这种“沟通-编码-返工”的死循环,本质源于技术实现与业务逻辑的割裂。

开发周期:从“敏捷”到“瀑布”的异化 传统开发流程的线性特征(需求评审→原型设计→编码→测试)在数据中台场景下尤为突出。某制造企业为构建设备故障预警模型,从算法选型到模型上线耗时4个月,而产线实际需求已随设备迭代发生变化,最终模型上线即面临二次重构。
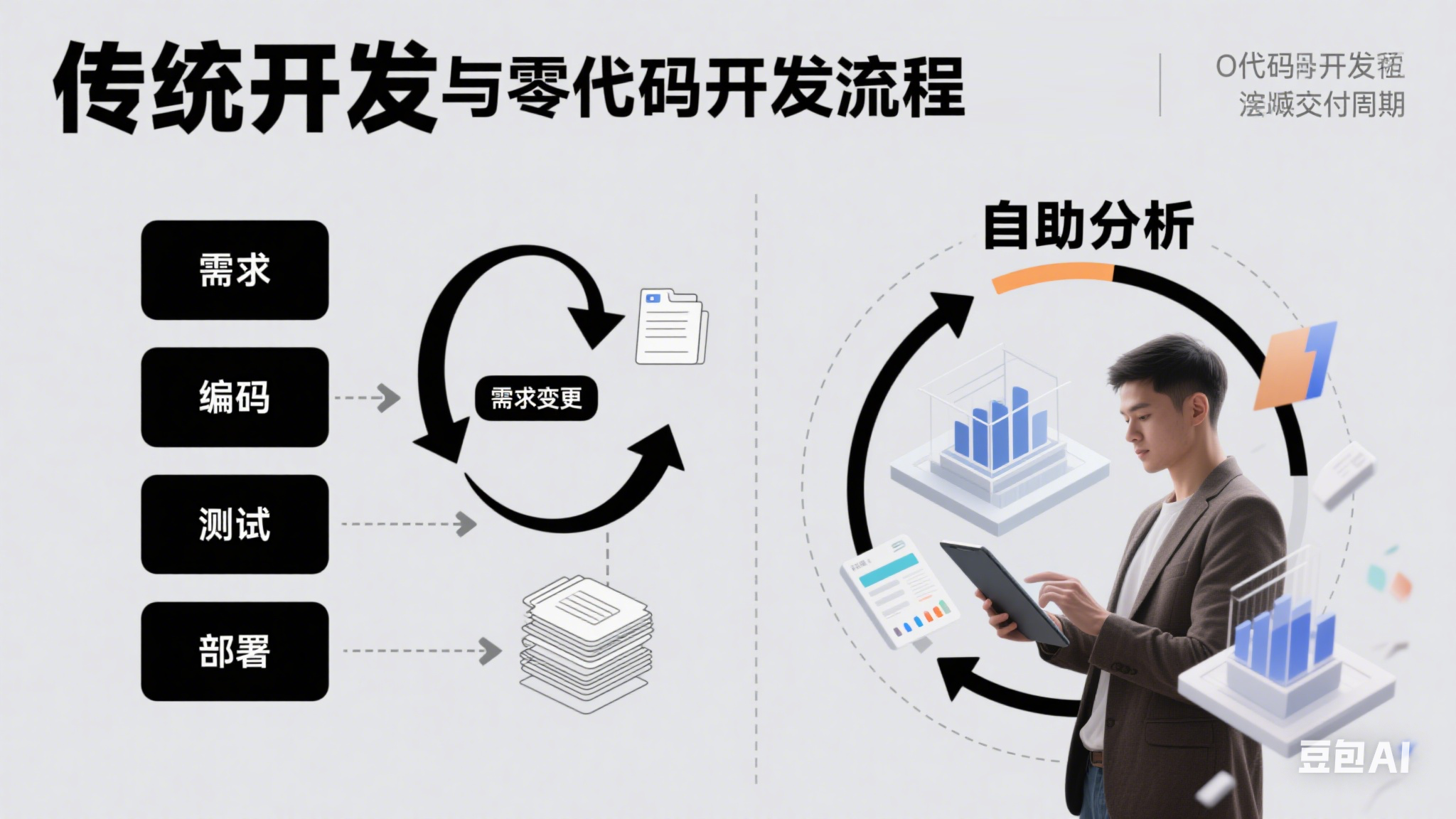
维护黑洞:代码的“不可逆熵增” 在金融行业某案例中,某风控模型因开发人员离职导致维护断档,新团队需花费2个月逆向解析数万行代码逻辑,期间因参数误调引发系统误判,直接损失超百万元。代码的复杂性与文档的缺失,让技术债务成为隐形炸弹。
业务逻辑的“可视化表达” 桐果云通过 组件化封装 与 流程引擎 ,将传统代码转化为可视化模块。例如,某电商企业用拖拽式组件构建用户分群模型:
数据接入层:直接连接用户行为日志、订单数据库、第三方埋点; 规则引擎:通过条件分支组件定义“近30天活跃度>80%”等高价值用户筛选逻辑; 模型输出:自动生成用户标签体系,并推送至CRM系统。 全程无需编写SQL或Python代码,业务人员独立完成开发,需求响应周期从3周缩短至8小时。
动态迭代的“乐高式架构” 传统代码开发中,模型迭代需重构底层逻辑(如修改决策树深度参数需调整代码结构),而零代码平台通过 参数化配置 实现动态调整。某物流企业基于桐果云优化路径规划模型时,仅需在界面修改“运输成本权重”“时效优先级”等参数,即可实时生成新方案,迭代效率提升10倍以上。
技术风险的“透明化管控” 平台内置 版本控制 与 血缘分析 功能,所有操作(如字段映射规则、算法参数调整)均以可视化流程图留存。当某能源企业出现数据波动异常时,运维团队通过回溯模型血缘关系,30分钟内定位到某外部数据源字段变更问题,避免传统模式下数天的排查成本。
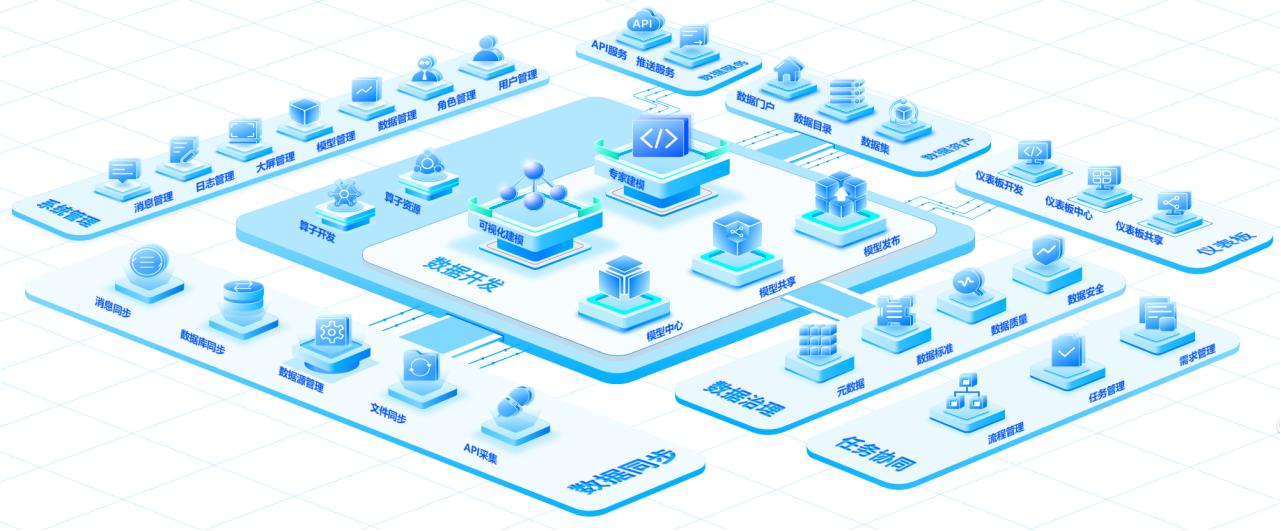
异构数据治理:从“脏数据”到“高质量资产”
智能映射引擎:自动识别数据库、CSV、kafka等不同来源数据的字段含义(如将“user_id”“UID”“用户编号”统一映射为“用户ID”); 异常检测规则库:预置空值检测、数值区间校验、关联性验证等规则。
数据工厂:算法开箱即用
预置算法仓库:涵盖常用数据统计、数据比对、数据提取、数据转换,还包括机器学习(如ARIMA、Prophet)、事件处理(发邮件、发短信)等200+算法;满足90%以上数据分析需求。
服务化输出:打破数据孤岛
API工厂:模型发布后自动生成Restful API,支持限流、鉴权、日志监控; 实时推送引擎:某零售企业将库存预测结果推送至门店POS系统,实现动态补货决策。
安全合规双保险
字段级权限控制:支持基于RBAC模型的数据脱敏; 审计追踪:所有数据操作留痕,满足GDPR等合规要求。
零代码并非“万能钥匙”,其价值在于 平衡效率与灵活性 :
适用场景:业务规则明确的中台模块(如报表体系、标准化分析模型); 扩展性设计:桐果云支持通过SDK接入自定义Python/Java代码,应对复杂计算场景; 生态兼容:与Kafka、BI组件无缝集成,保护企业原有技术投资。
数据中台的核心使命是让业务用数据“说话”,而非让技术用代码“炫技”。零代码技术通过降低使用门槛、加速需求闭环,正在推动数据中台从“技术项目”向“业务工具”进化。对于企业而言,或许不必纠结于“写不写代码”,而应关注如何让数据能力真正嵌入业务决策链——毕竟,数字化转型的终点,是“人”的转型,而非“代码”的堆砌。
 桐果云深度理解不同行业的业务逻辑,将通用的自动化能力,转化为解决您特定痛点的钥匙。
桐果云深度理解不同行业的业务逻辑,将通用的自动化能力,转化为解决您特定痛点的钥匙。
 告诉我们您的行业与难题,剩下的,交给我们。
告诉我们您的行业与难题,剩下的,交给我们。
 免费咨询,获取定制化思路
免费咨询,获取定制化思路

免费试用&商务合作
在线体验(基础版):https://cloud.jintt.cn
👇扫描二维码联系我们,获取免费试用和预约专家咨询

👇关注我们,了解更多









 扫码咨询
扫码咨询


全部评论